n8n ist ein mächtiges Open-Source-Automatisierungswerkzeug. Sobald es in Produktion geht, stellt sich unweigerlich die Frage: Wie merke ich, wenn ein Workflow fehlschlägt?
Dieser Artikel zeigt, wie ihr n8n Workflows mit Grafana vollständig observierbar macht.
Warum Monitoring für n8n-Workflows?
n8n-Workflows laufen oft unsichtbar im Hintergrund: Daten werden synchronisiert, Benachrichtigungen verschickt, Geschäftsprozesse automatisiert. Ohne Monitoring bleiben Fehler lange unentdeckt. Typische Probleme sind:
- Workflows, die still fehlschlagen und keine Fehlerbenachrichtigung auslösen
- Laufzeiten, die sich schleichend verschlechtern und auf Engpässe hinweisen
- Warteschlangen, die sich bei Lastspitzen aufbauen
- Externe Abhängigkeiten (APIs, Datenbanken), die flaky werden
Lokales Setup
Zur Veranschaulichung können wir uns relativ schnell ein kleines lokales Setup mit "docker compose" aufbauen. Wir benötigen hierzu die Services n8n, postgresql und grafana. Wichtig hier ist das dies auf keinen Fall so als Produktivsystem verwendet werden darf. Dies dient nur der Veranschaulichung!
# docker-compose.yml
services:
n8n:
image: n8nio/n8n:latest
restart: unless-stopped
ports:
- "5678:5678"
environment:
- N8N_HOST=localhost
- N8N_PORT=5678
- N8N_PROTOCOL=http
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_DATABASE=n8n
- DB_POSTGRESDB_USER=user
- DB_POSTGRESDB_PASSWORD=password
volumes:
- n8n_data:/home/node/.n8n
postgres:
image: postgres:16-alpine
environment:
POSTGRES_DB: n8n
POSTGRES_USER: user
POSTGRES_PASSWORD: password
volumes:
- postgres_data:/var/lib/postgresql/data
grafana:
image: grafana/grafana:latest
restart: unless-stopped
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/grafana
volumes:
n8n_data:
postgres_data:
grafana_data:
Die Services können anschließend mit "docker compose up -d" gestartet werde.
Grafana konfigurieren
Sobald die Services laufen kommt ihr über "localhost:3000" auf Grafana und könnt euch dort dann über den Default Zugang "admin:admin" einloggen.
Legt euch dann ein Verbindung zu eurer Postgresql Datenbank an. Hier greifen wir direkt auf unsere n8n Datenbank zu. Verwendet die Credentials, die ihr zuvor in eurer "docker-compose.yml" gesetzt hattet. Verwendet als Host URL "postgres:5432"
Nachdem eine Verbindung innerhalb von Grafana zu der Postgres DB aufgebaut wurde können wir uns an das Dashboard machen, das wir uns nicht selbst erarbeiten müssen. Wir können hier auf ein Dashboard aus der Community zurückgreifen. Credits gehen hier an den User "nluecke".
Wir können uns direkt über Dashboards->Import ein neues Dashboard anlegen.
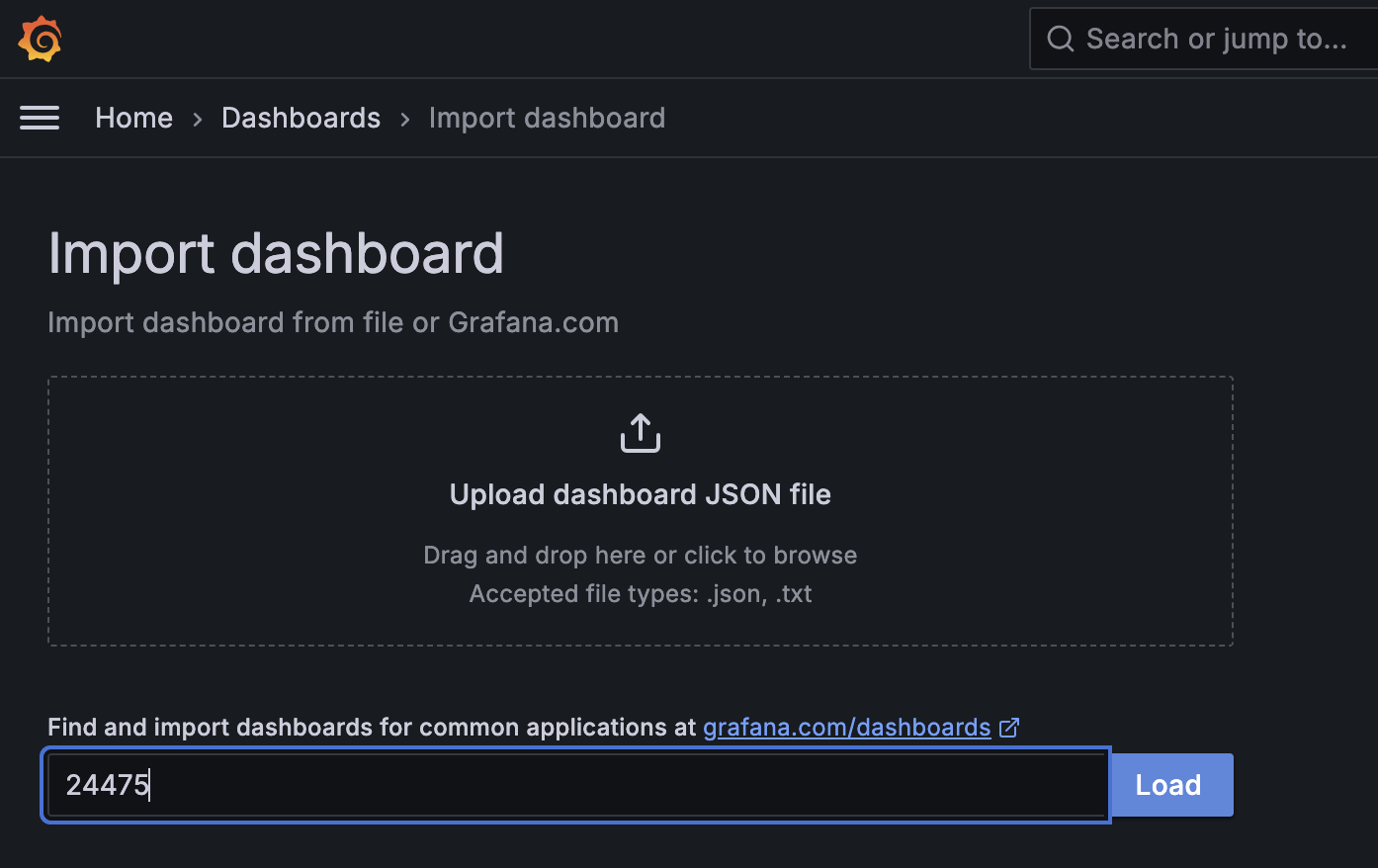
In dem folgenden Formular können wir relativ simpel über die ID "24475" das Community Dashboard importieren.
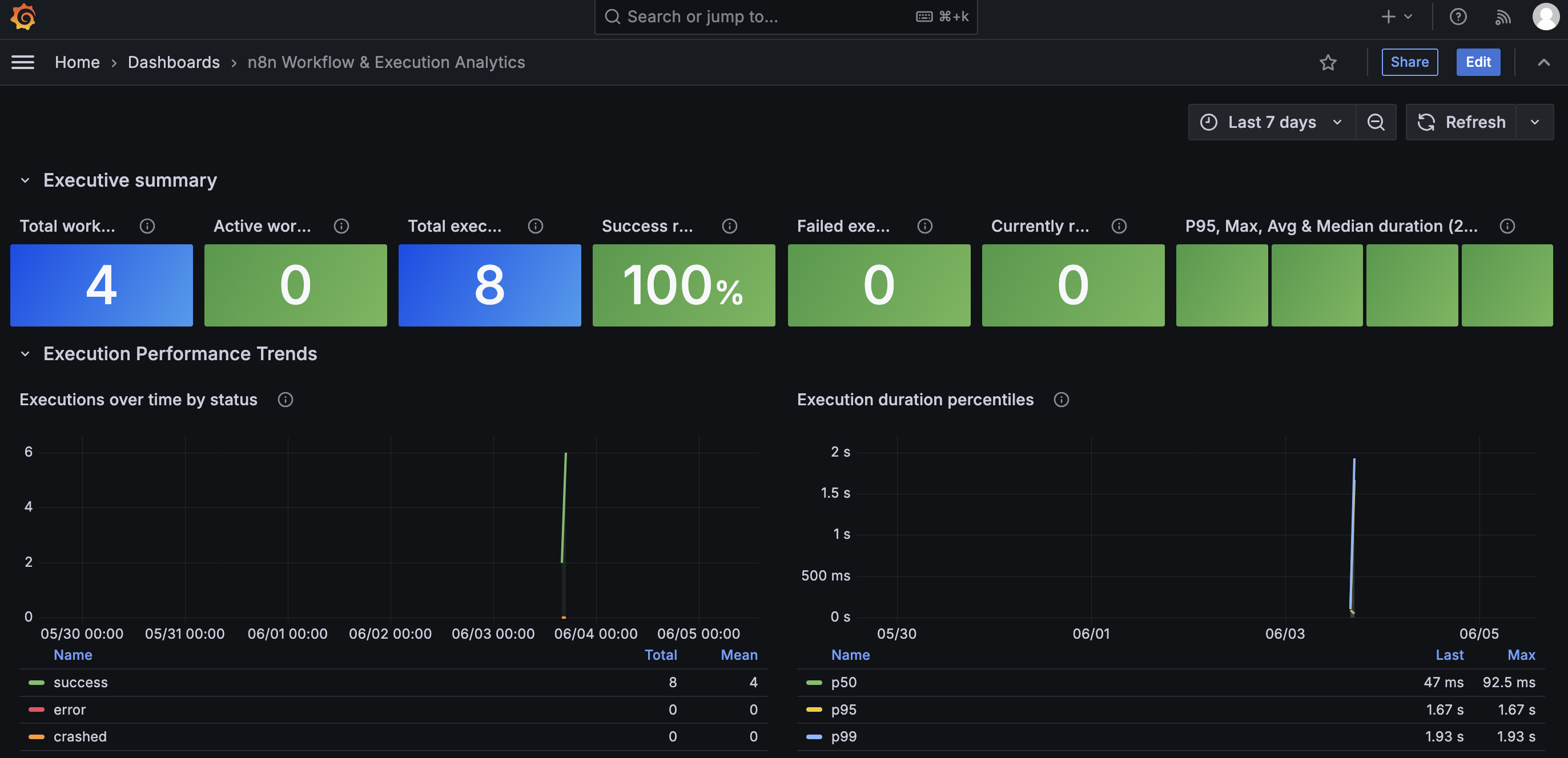
Wir erhalten direkt ein Dashboard in dem viele nützliche Workflow Metriken angezeigt werden:
- Anzahl erfolgreicher bzw. fehlerhafter Workflows
- Ausführungsdauer von Workflows im Zeitverlauf
- Am Häufigsten ausgeführte Workflows
- Langsamste Workflows
- Workflows mit den meisten Fehlern
- ...
Ausblick
Falls einem das nicht ausreicht lässt sich dieses Dashboard auch als Ausgangsbasis verwenden und individuell anpassen. Außerdem ist es auch möglich zuätzlich noch Prometheus einzusetzen um auch mehr auf die Performance von n8n selbst zu schauen. Auch dafür gibt es ein Template aus der Community.
Für sämtliche Metriken können innerhalb von Grafana auch Alarmierung eingebaut werden, die beispielsweise per Mail oder Slack Nachricht benachrichtigen, wenn Workflows länger als X Minuten laufen.
Wir haben gesehen, dass sich so ein Monitoring sehr schnell aufbauen lässt. Für ein Produktivsystem ist Monitoring definitiv nicht optional!
Wer tiefer in Grafana und Prometheus einsteigen möchte, findet in unseren Schulungen den strukturierten Einstieg mit Hands-on-Labs und echten Szenarien.
Tiefer einsteigen?
In unseren Live-Online-Schulungen lernt ihr Grafana und Prometheus praxisnah inklusive eigener Lab-Umgebung und kleiner Gruppen kennen.